


AMPERE develops a new generation of computing software and systems design ecosystem for applications in industrial sectors with tight interactions among subsystems Cyber-Physical Systems of Systems (CPSoS). The ecosystem aims at helping system developers to leverage low-energy and highly-parallel and heterogeneous computation in their development process while fulfilling the non-functional constraints inherited from the cyber-physical interactions.
The main challenge addressed in AMPERE is to bridge the gap currently existing between the techniques used for the construction of complex CPSoS, and the techniques used for effectively exploiting parallel architectures:
- Model-Driven Engineering (MDE) is a common methodology for the development of complex systems mainly because of two reasons: it allows formal verification of functional and non-functional requirements with composability features, and it enables the use of code generation tools for a development process based on a correct-by-construction paradigm.
- Parallel Programming Models (PPMs) are mandatory for achieving productivity on parallel architectures, in terms of programmability, portability, and performance.
AMPERE’s use cases target the automotive and railway domains. CPSoS offers the opportunity to leverage low-energy and highly-parallel and heterogeneous systems, while fulfilling the non-functional constraints on these domains, opening the door to the development of more efficient and autonomous mobility solutions. Nonetheless, AMPERE’s developments are also applicable to other domains with the same or similar constraints, like industrial control systems, and robotic systems, among others.
Software Ecosystem
The figure below shows a schematic view of the AMPERE software ecosystem stack and the set of layers to be integrated:
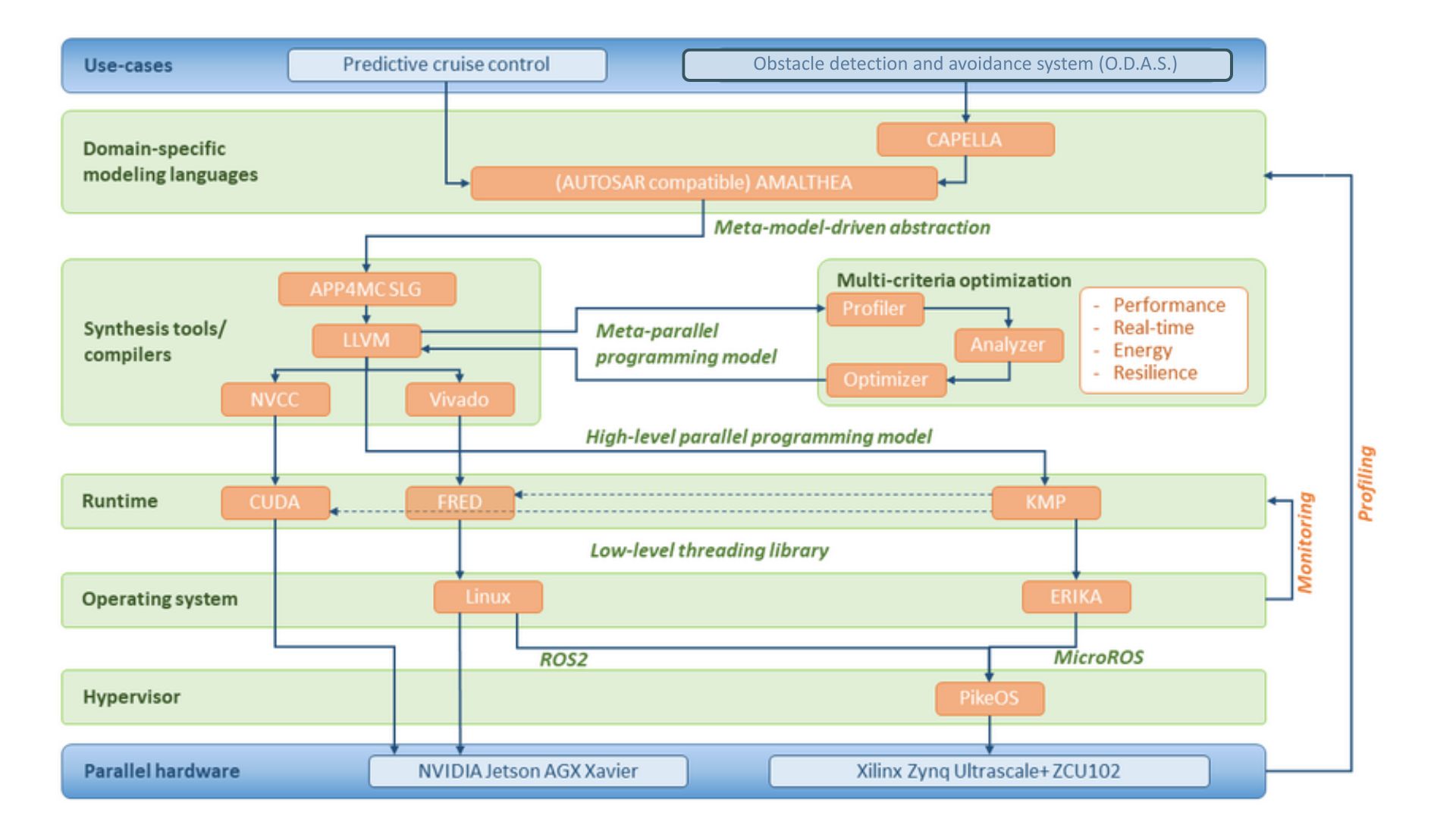
AMPERE devises a complete system design and computing software ecosystem including the complete stack for designing, implementing, and efficiently executing dependable and physically-entangled systems on platforms composed of the most advanced Commercial-Off-The-Shelf (COTS) energy-efficient parallel heterogeneous architectures.

Watch technical demos by clicking the icon above.